[Optimism] Velodrome Locks
Loading...
Loading...
Loading...
Loading...
Dashboard Objectives
- The dashboard will look at the new lockups being created on Velodrome Finance.
- It will attempt to derive insights into the lock-up periods preferred by the users.
- It will also delve Pool Voting stats and behavours.
Author:
- Twitter: @lelaughingman
- Flipside Bounty Hunter: TheLaughingMan
- Discord: TheLaughingMan#3062
QUICK! Lock it up!!! Lock it up!!
- Taking a glance at
Chart 1to the right, we can spot 4 distinguishable lines across the scatter plot. - These lines are roughly at the following levels:
- 0-1 Weeks
- 4-5 Weeks = ~ 1 Month
- 48-51 Weeks = ~1 year
- 200 Weeks = ~ 4 years
These levels seem to be of interest…🧐
Proceeding further with Charts 2 & 3….
- The figures on these charts also corroborate the keen interest around the aforementioned levels
- 1 year and lesser periods have mediocre interest…
- The higher extremes (3 and more years) periods have the highest participation.
- The middle ground periods (1-3 years) have the least interest…
Now that we know what the spans are, let’s hop on to the next logical question! …
Y deez specific duration spans though? 🤔🤔
-
The primary factor for choosing these spans is likely the basic crypto-enjoyer instinct:
Numba Go Up -
The longer the span chosen, the better the lockup reward rate as follows:
1 VELO locked for 4 years = 1.00 veVELO 1 VELO locked for 3 years = 0.75 veVELO 1 VELO locked for 2 years = 0.50 veVELO 1 VELO locked for 1 years = 0.25 veVELO
BUT WAIT! THERE’S MORE! ↗️↗️↗️
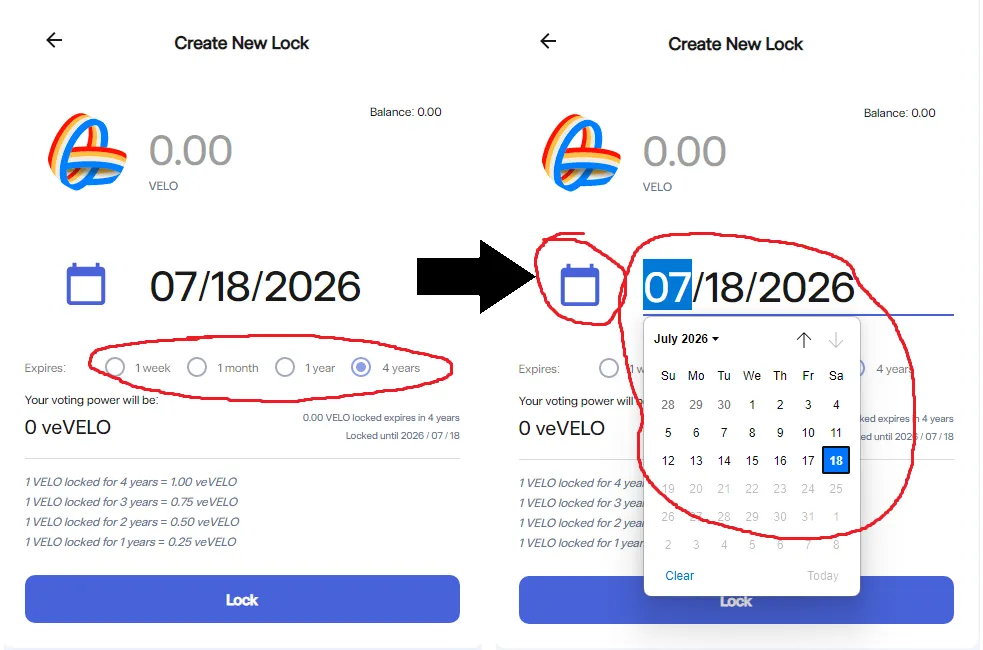
Human Psychology / Velodrome User Interface
- The interface kind of makes it appear that the only valid/best choices for a user are the four radio-button options readily provided! That and the text below the buttons explaining the rates further would tell the User’s mind to concentrate/decide among only these 4 options 🤯
- However, as the image (the bottom-right of this panel) shows if you click either the calendar icon, or manually type in the values, you can pick a ‘custom’ lockup period!
- The custom inputs can also be seen on-chain 🕵️
veVELO Pool Voting
- We take a glance at the Voting favorites/preferences the platform’s most users have opted to vote for so far.
- The analysis can be viewed in Streamlit - here
Analysis Issues/Difficulty
- There was a roadblock limiting the usual analysis via velocity/snowflake.
- The voting data:
-
pool_addresses/token_ids
-
voting_weights/power
was present in a dynamic hex string as follows:
# MethodID: 0x7ac09bf7 # [0]: 0000000000000000000000000000000000000000000000000000000000001077 # [1]: 0000000000000000000000000000000000000000000000000000000000000060 # [2]: 00000000000000000000000000000000000000000000000000000000000000a0 # [3]: 0000000000000000000000000000000000000000000000000000000000000001 -> pool count N # [4]: 00000000000000000000000079c912fef520be002c2b6e57ec4324e260f38e50 -> N pools # [5]: 0000000000000000000000000000000000000000000000000000000000000001 -> weight count N # [6]: 0000000000000000000000000000000000000000000000000000000000002710 -> N weights
-
- Given the number of pools and their corresponding weights could vary from transaction to transaction, stronger programmability was needed! Hence, python/streamlit to the rescue!
Basic Algorithm:
-
Pulling all vote transactions with a simple SQL query:
SELECT block_timestamp, tx_hash, from_address, input_data from optimism.core.fact_transactions WHERE input_data LIKE '0x7ac09bf7%' AND to_address = '0x09236cff45047dbee6b921e00704bed6d6b8cf7e' -
Once we have the unrefined input_data, Python takes over
output = [] for row in data['results']: # remove long_hex = row[3].split('0x7ac09bf7')[1] # break up string into 64 length groups hex_rows = wrap(long_hex, 64) token_id = int(hex_rows[0], 16) pools = [] weights = [] #get each address from row 5 onward based on count, fix the address string for i in range(0, int(hex_rows[3], 16)): pools.append('0x'+ hex_rows[4 + i][24:]) #get each weight for i in range(0, int(hex_rows[3 + len(pools) + 1], 16)): weights.append(int(hex_rows[3 + len(pools) + 2 +i], 16))