Sushi pairs on Avalanche and BSC
Q108. Let's dive deep into Sushi pairs on Avalanche and BSC
In this dashboard we will dive into:
- Create a document that includes all addresses for all Swap pairs on Avalanche for sushi, plus the addresses of the two tokens belonging to each pair.
- Create a document that includes all addresses for all Swap pairs on the BSC chain for sushi, plus the addresses of the two tokens belonging to each pair.
- Create a document that includes all addresses for all Kashi pairs on Avalanche for sushi, plus the addresses of the two tokens belonging to each pair. Ideally, define which one is the main asset and which one is the collateral.
- Create a document that includes all addresses for all Kashi pairs on the BSC chain for sushi, plus the addresses of the two tokens belonging to each pair. Ideally, define which one is the main asset and which one is the collateral.
Methodology
I chose to go through this dashboard by scrapping and using the links of pools in sushiswap website and to be more precise, I used the info from the following links:
- Kashi pairs on Avalanche on sushiswap
- Kashi pairs on BSC on sushiswap
- Swap pairs on Avalanche on sushiswap
- Swap pairs on BSC on sushiswap
After retrieving the necessary data, from the above links, I needed to work on the JSON retrieved data so I can select the related columns to show. I used pandas library of python for this task. I will put a sample code for doing this part.
And finally I figured probably the best way to show the results in a neat way is to share my analytics in Google sheets.
So here are the results to four needed categories:
On the next parts, I will put a sample screenshot of how my result table looks like.
Note: As I used the data from outside of Flipside, I didn’t write queries, but in order to be eligible to submit my dashboard I added one simple query to calculate the number of Kashi pools on Avalanche.
The sample code for tables
import json, pandas as pd
data = {}
with open('avax.json', 'r') as f:
data = json.load(f)
df = pd.DataFrame(columns=['pair-name', 'swap-address', 'token0_symbol','token0_name',
'token0_contract_address', 'token0_decimals', 'token1_symbol',
'token1_name', 'token1_contract_address', 'token1_decimals' ])
for i in range(len(data)):
df = df.append({ 'pair-name': data[i]['pair']['token0']['symbol'] + '-' + data[i]['pair']['token1']['symbol'],
'swap-address' : data[i]['pair']['id'],
'token0_symbol' : data[i]['pair']['token0']['symbol'],
'token0_name' : data[i]['pair']['token0']['name'],
'token0_contract_address' : data[i]['pair']['token0']['id'],
'token0_decimals' : data[i]['pair']['token0']['decimals'],
'token1_symbol' : data[i]['pair']['token1']['symbol'],
'token1_name' : data[i]['pair']['token1']['name'],
'token1_contract_address' : data[i]['pair']['token1']['id'],
'token1_decimals' : data[i]['pair']['token1']['decimals']}, ignore_index=True)
df.to_csv (r'avax_final.csv', index = None)
So here, I took every JSON files related to the raw data from Sushiswap, and I created a Dataframe in a way that I wanted so I could have the columns I need from it.
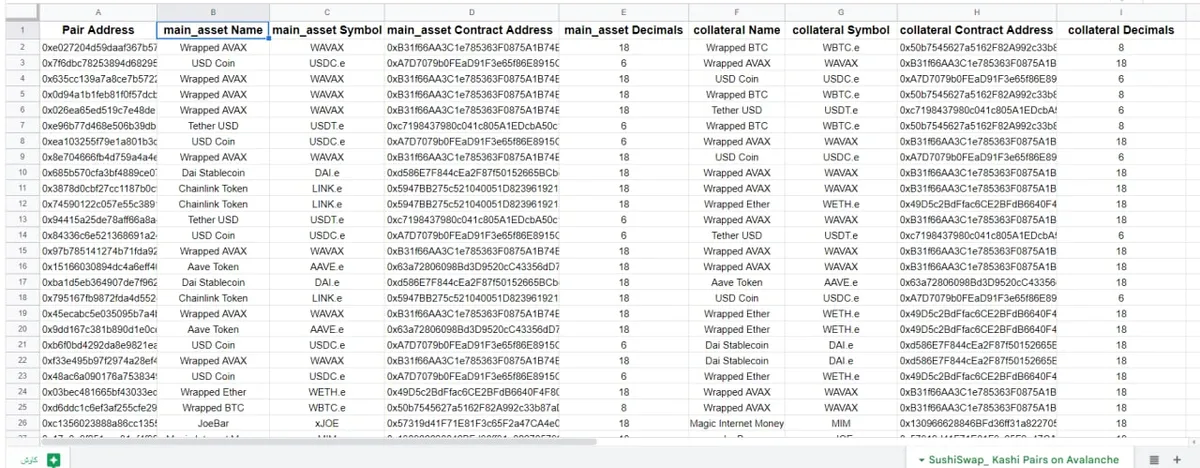
Kashi Pairs
In the results of Kashi pairs for both Avalanche and BSC, we can see the these columns:
| Pair Address | main_asset Name | main_asset Symbol | main_asset Contract Address | main_asset Decimals | collateral Name | collateral Symbol | collateral Contract Address | collateral Decimals |
|---|
So as the question asked, I made the main asset and collateral clear here, also added decimals for each one.
There is a screenshot of Kashi pairs on Avalanche.